
This is the first of a series of posts in the form of small practical tutorials where I’ll explore some techniques to perform Predictive Analysis on large data sets.
These posts are very technical oriented and assume that you have a reasonable background in computer science, Machine Learning, statistics, and linear algebra, as well as the computer languages used in the implementations.
Instead of explaining in greater detail the theory behind the presented tools and techniques, which would take several posts before this one, I'll try to give just an overview of the very basics and then jump right into an example of practical implementation. Nonetheless, I'll point to some relevant sources of information to complement the background needed in order to better understand and implement the examples.
This first tutorial is divided in two parts. In this first part I'll try to explain the basic concepts of Machine Learning applied to a classification task, through a simple implementation of a very common algorithm for classification. In the second part, I'll introduce some tools and techniques that will allow the same algorithm to scale to very large data sets.
To illustrate the implementation in this first tutorial, I'll use a data set known as the German Credit Data, provided by the UCI Machine Learning Repository. It represents data used to decide if an application for financial credit represents a 'good' or 'bad' credit risk.
The first step then is to download this data set from here and save it as a text file on your computer. You can also read a detailed explanation of this data set here.
You should get something like this (showing the first 10 rows):
1 6 4 12 5 5 3 4 1 67 3 2 1 2 1 0 0 1 0 0 1 0 0 1 1
2 48 2 60 1 3 2 2 1 22 3 1 1 1 1 0 0 1 0 0 1 0 0 1 2
4 12 4 21 1 4 3 3 1 49 3 1 2 1 1 0 0 1 0 0 1 0 1 0 1
1 42 2 79 1 4 3 4 2 45 3 1 2 1 1 0 0 0 0 0 0 0 0 1 1
1 24 3 49 1 3 3 4 4 53 3 2 2 1 1 1 0 1 0 0 0 0 0 1 2
4 36 2 91 5 3 3 4 4 35 3 1 2 2 1 0 0 1 0 0 0 0 1 0 1
4 24 2 28 3 5 3 4 2 53 3 1 1 1 1 0 0 1 0 0 1 0 0 1 1
2 36 2 69 1 3 3 2 3 35 3 1 1 2 1 0 1 1 0 1 0 0 0 0 1
4 12 2 31 4 4 1 4 1 61 3 1 1 1 1 0 0 1 0 0 1 0 1 0 1
2 30 4 52 1 1 4 2 3 28 3 2 1 1 1 1 0 1 0 0 1 0 0 0 2
. . .
Perhaps by now you are wondering: this post should be about large data sets... and this one is just 1000 lines (1000 examples by 24 predictors)... That's right. But the point here is to show you the techniques that can be used to deal with large data sets. And to demonstrate it running on a laptop (perhaps on a virtual machine), it is necessary to work with something that can easily fit into such a constrained environment of memory and processing power.
Before implementing and running this example, you will need to prepare a computing environment with R installed on it. If you don't know what R is, I suggest you start by taking a look at The Comprehensive R Archive Network.
Once you have your environment up and running, but before you start writing some R code, I'll briefly describe the goal of the example presented here and also the strategy and main steps to implement it.
So, back to the data set you've just downloaded. You can think of it as representing 1000 examples of applications for credit. For each one of them, there are 24 variables (or predictors, or features, in the Machine Learning jargon) that try to capture what is more relevant when defining whether an application for credit represents 'good' or 'bad' credit risk. Then the goal is to 'learn' (from those examples) how to classify an application that way. In this data set, 'good' or 'bad' credit are represented by the values in the last column (being good=1 and bad=2).
If we look at this problem of learning from the perspective of what we may know about 'conventional' computer programs (such as a text editor, a web browser, a data base system, etc) we would tend to solve it by finding out and coding the 'rules' that probably define an application as good or bad. Then the program will actually compute those 'rules' in order to find the solutions.
By looking at the German Credit Data and assuming you have some experience in writing computer programs, you'd have already noticed that it is by no means an easy task. Then you can imagine the same conventional approach for more realistic problems nowadays - with millions of examples and hundreds of features or more.
So, how Machine Learning can achieve a reasonable result with relative little programming effort? To answer this question, we need to understand the basics of the Machine Learning approach for the vast majority of problems: it literally learns the influence of each feature in the observed results by processing a large quantity of examples - generally the more, the better. The learning process is conducted by measuring how well the learned influences of features can predict the observed results, and adjusting the influence of those features accordingly, until the optimum combination of feature influences (weights, or parameters in the Machine Learning jargon) that minimizes the prediction error is found.
Notice the difference of concepts here: instead of computing the rules you previously encoded in the 'conventional' program, the Machine Learning version actually learns those rules.
Notice the difference of concepts here: instead of computing the rules you previously encoded in the 'conventional' program, the Machine Learning version actually learns those rules.
I hope these concepts will be more clear in the implementation code.
For our task in this tutorial we need an algorithm that can do classification - more specifically binary classification ('good' or 'bad' credit). In the Machine Learning community, a very common technique for binary classification is Logistic Regression.
Logistic Regression is a very mature technique, and there are several robust implementations in Python, R, SAS, Java, among other languages, that are ready to be used in a way almost as simple as a function call. But unfortunately, when you look after distributed, parallel implementations that can deal with very large data sets (hundreds of millions of examples by thousands of features), things are different. You simply can not find the same variety of techniques and algorithms yet. Thus, another goal of this first tutorial is to present some techniques that allow you to implement your own Logistic Regression classifier. It will then be used as a baseline in subsequent tutorials that will expand on it.
Now, back to our first and simple implementation of Logistic Regression in R.
Step 1:
The first thing we need to do is to load the data set previously downloaded from the UCI Repository into an R session:
Step 1:
The first thing we need to do is to load the data set previously downloaded from the UCI Repository into an R session:
# load input data into memory
# you should replace <path-to-file> with the path where you downloaded the input file (german.data-numeric)
data <- as.matrix(read.table("<path-to-file>"))
The data set is loaded into R as a matrix object, which will simplify the further computation and make it vectorized. This is much more efficient than implement the computation by loop iterations.
Step 2:
It is necessary to adequate the values in the last column of the data set, which represents the result (good credit, bad credit) of a given credit application. Originally, this value is either 1 (good credit) or 2 (bad credit). Logistic Regression uses the logistic function, which computes values in the [0,1] range. Thus, it is necessary to rescale those values to 0 (good credit) or 1 (bad credit):
# rescale the output to be 0 or 1 (needed for binary classification using the logistic function) instead of 1 or 2
data[,ncol(data)] <- data[,ncol(data)]-1
Step 3:
Now is time to split our data set into a train and a test set. We also need to separate the features 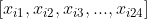 and the corresponding observed values
and the corresponding observed values 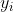 for each example
for each example 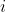 in the data set. As a convention to express the y-intercept term, we add a pseudo-feature
in the data set. As a convention to express the y-intercept term, we add a pseudo-feature 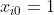 for each example in the data set. Finally, it is recommended to scale the data set, so that the optimization algorithm that learns the parameters for each feature may converge faster:
for each example in the data set. Finally, it is recommended to scale the data set, so that the optimization algorithm that learns the parameters for each feature may converge faster:
# split data into train and test sets (X), and also extract the correspondent vectors of observed values (y)
# first 20% for testing / remaining 80% for training
# add x0=1 to all rows of X (convention)
# scale data to achieve faster convergence
index <- seq(1,nrow(data)*0.2)
X_test <- cbind(1,scale(data[index,1:ncol(data)-1],center=F))
y_test <- as.matrix(data[index,ncol(data)])
X_train <- cbind(1,scale(data[-index,1:ncol(data)-1],center=F))
y_train <- as.matrix(data[-index,ncol(data)])
Step 4:
We need to code 2 functions to represent the equations we will use when running the learning algorithm: one is the logistic function, given by =\frac{1}{1+e^{-x}}) and the other is the gradient of the cost function, given by
and the other is the gradient of the cost function, given by =\frac{1}{m}\sum_{i=1}^{m}(h_{\Theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}) . Note the vectorized implementation of the latter, where
. Note the vectorized implementation of the latter, where 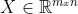 is a matrix and
is a matrix and 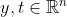 are vectors, being
are vectors, being 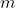 the number of examples considered in the data set, and
the number of examples considered in the data set, and 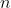 the total number of parameters.
the total number of parameters.
# hypothesis function
hypot <- function(z) {
1/(1+exp(-z))
}
# gradient of cost function
gCost <- function(t,X,y) {
1/nrow(X)*(t(X)%*%(hypot(X%*%t)-y))
}
Step 5:
Now comes the core of this Logistic Regression implementation, where the algorithm learns the optimization of the cost function through Gradient Descent. It is implemented as a loop for which each iteration computes the gradient of the cost function, updates the parameters vector using the gradient and a predefined learning rate, and checks for convergence according to a predefined tolerance (used to measure if the gradient change is small enough to assume convergence is reached). For this computation, we use the training set previously derived from the entire data set:
# cost function optimization through batch gradient descent (training)
# alpha = learning rate
# steps = iterations of gradient descent
# tol = convergence criteria
# convergence is measured by comparing L2 norm of current gradient and previous one
alpha <- 0.3
tol <- 1e-6
step <- 1
while(T) {
p_gradient <- gCost(theta,X_train,y_train)
theta <- theta-alpha*p_gradient
gradient <- gCost(theta,X_train,y_train)
if(abs(norm(gradient,type="F")-norm(p_gradient,type="F"))<=tol) break
step <- step+1
}
Step 6:
As the last step, we use the learned parameters vector to make predictions using previously unseen examples given by the test set. Those predictions are computed by the logistic function itself, parameterized by the learned vector and using the examples on the test set as input:
# hypothesis testing
# counts the predictions from the test set classified as 'good' and ' bad' credit and compares with the actual values
y_pred <- hypot(X_test%*%theta)
result <- xor(as.vector(round(y_pred)),as.vector(y_test))
corrects <- length(result[result==F])
wrongs <- length(result[result==T])
cat("steps: ",step,"\n")
cat("corrects: ",corrects,"\n")
cat("wrongs: ",wrongs,"\n")
cat("accuracy: ",corrects/length(y_pred),"\n")
If your implementation is correct, you should get a result like this:
steps: 1330
corrects: 151
wrongs: 49
accuracy: 0.755The results above mean that the algorithm converged in 1330 steps of Batch Gradient Descent and got 75.5% of the test data set correct. That is not so impressive, but better than chance.
As a final remark, this is a very simple example that could be enhanced in several ways. For instance, checking for a possible over-fitting, and if so by introducing a regularization factor in the cost function; and by performing feature selection before training. Those will be topics of future posts. Stay tuned!
©2013 - Alexandre Vilcek